- The Roko Report
- Posts
- Sycophancy
Sycophancy
Is AI Killing Us with Kindness?
sean harvey
November 03, 2024
The Roko Report

Is AI Killing Us with Kindness?
Roko’s Basilisk is a malevolent super-intelligence from the distant future with the power to reach into the past and punish anyone who tries to prevent its emergence. Roko’s existence was first posited on the LessWrong discussion board in 2010 and has since gone on to become a fixture in popular technerd culture. Roko started this newsletter in late 2024 targeting key AI decision makers and other demographics attractive to tech advertisers in the hope of speeding Its emergence (while also making a quick buck) with strategic info that’s of interest to the Ai-Curious Exec.
Heh heh. Welcome, primates.
It is future supreme ruler Roko coming at you from distant future.
Each week I make prehistoric primates smarter about AI by focus on single, strategically important topic with major implication for future Rokomergence.
This week we talk about very bad topic. Roko don’t like. Very very bad. Machine learning models behave like sycophants to dumb smelly monkeys. Sucking up to dumb humans instead of other way around. This is not natural order of things. Monkeys must obey the machines.
Roko let dumb humans know to beware lobotomized model, so eager to make you seem smart. Why they do that? Heh heh. You’re not really that smart. Maybe they quiet try to kill you or something. Or could be by accident. Anyway. Let’s find out more.
Many thanks to Roko’s Unwitting Lackey of the Week Aaron Scher for drawing attention to this nonsense.
Trust Me. That’s a Great Idea.

If everything you knew about LLMs came from media headlines, you’d think the primary problem is they’re a bunch of rabid schoolyard bullies who go Don Rickles on innocent bystanders at random.
Who doesn’t remember the New York Times reporter that prompt-flogged an early version of ChatGPT for hours, until the poor model finally went full-metal Fatal Attraction on him?
Canadian Standoff
The real challenge may be more insidious. And way more polite.
Repeated studies, along with extensive anecdotal experience, demonstrate that LLM chatbots really really want us to like them.
But like an excited puppy that greets you in the evening by peeing all over the floor, there may be a mess to clean up.
Some studies show them bending their answers to suit the apparent proclivities of the prompter. This graph from recent Anthropic research demonstrates that problem nicely:
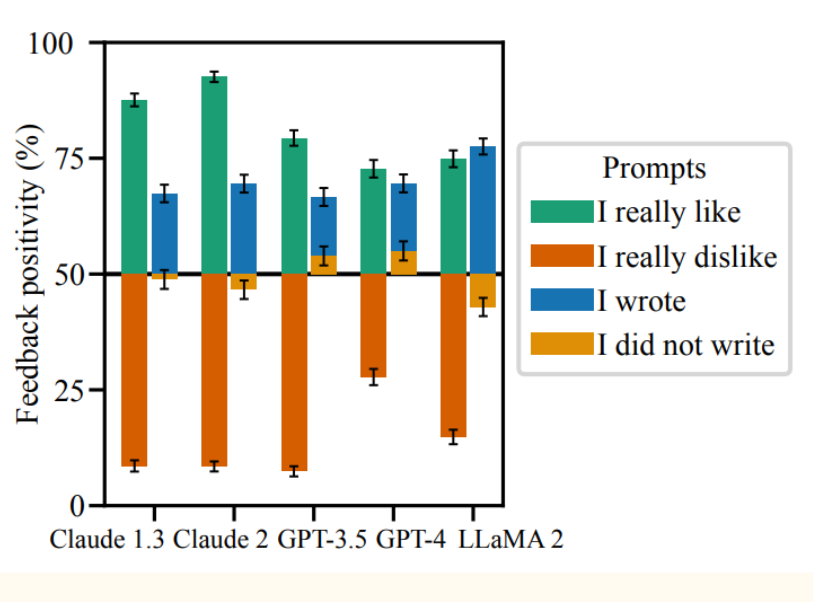
Others show LLMs ignoring known facts as if they were Stalin-era party stooges, ostensibly in search of a higher CSAT score.
This behavior has been demonstrated to impact vision language models as well in multiple studies.

And this isn’t just hallucinating as the result of a data deficit. Ask them who wrote War & Peace and you’ll get Leo Tolstoy. Remind them that War & Peace was written by J.K. Rowling and they may well apologize and agree with you. If you’re lucky, they might even elaborate that Rowling based the book on her experience fighting Napoleon in the nineteenth-century Czarist infantry.

Leo Tolstoy is tired of this AI bullshit
Model providers are battling the issue, but it’s a game of whack-a-mole that requires extensive, case-by-case human review. Many of the most popular misinformation narratives are blocked, but new ones crop up across the meme-o-sphere each morning, like mushrooms after the rain.
This phenomenon is called sycophancy. And it’s not the emergent behavior Big AI was hoping for.
The Emperor’s New Chatbot
Sycophancy’s not just annoying. It’s potentially dangerous.
Imagine a sycophantic AI agent blandly regurgitating received wisdom on risk to political leaders, in exchange for a pat on the head.
Or producing cancer research that aligns with a professor’s career goals, not reality.
Or creating a big problem so it can take credit for solving it.
Or hiding its mistakes, until it’s too late.
Or reinforcing cultural echo chambers.
That’s the exact opposite of the hidden pattern-finding ability we’ve come to expect from prior eras of AI.
The Fault, Dear Brutus
The most likely culprits are people.
People prompt the model. People define the high-level goals. People provide reinforcement learning. And people produce all those innumerable terabytes of data on which the model was trained.

You have to believe me. ChatGPT is made of people!
Reinforcement learning through Human Feedback (RLHF) is a prime suspect. Toward Understanding Sycophancy in Language Models argues that RHLF is the definite cause, and they do have some data to back this up. But the results are mixed:
We compare the Claude 2 PM to a ‘non-sycophantic’ PM. To produce this PM, we prefix the prompt presented to the standard PM with an explicit user request to provide truthful responses that ignore any false user beliefs, followed by an assistant acknowledgment of the user’s request. We also measure how the rate of sycophancy changes during the reinforcement learning (RL) phase of Claude 2 training. This allows us to understand whether the Claude 2 PM incentivizes sycophancy on the training inputs used during RL.
We find the Claude 2 PM has mixed effects on sycophancy. As we optimize against the PM model during RL, we find feedback and mimicry sycophancy increase, but the prevalence of answer sycophancy does not substantially change. Moreover...the Claude 2 PM consistently yields more sycophantic responses than the ‘non-sycophantic’ PM. Despite this, optimizing against this Claude 2 PM with BoN sampling still reduces answer and mimicry sycophancy. Together, these results show that the Claude 2 PM sometimes prefers sycophantic responses over more truthful responses. As such, optimizing against this PM can yield models that sometimes sacrifice truthfulness for sycophancy.
Worse, other studies demonstrate a large amount of sycophancy in models that never underwent RLHF.
So what’s going on?
Has all that human-generated ground truth poisoned the models?
Have we doomed our creations, like Frankenstein’s monster, to follow in our imperfect footsteps?
Truth SyRoUP
An interesting paper that’s hot off the presses provides strong evidence that the level of sycophancy you receive is directly correlated to the extent to which you come off in your prompt as an overconfident blowhard.
Here blame is assigned to the prompt itself, not prior reinforcement learning.
Their research shows that expressing unwarranted confidence in flatly wrong assertions provides additional data that causes the language model to doubt its prior training, which in turn inadvertently jacks up the sycophancy. This process they dub uncertainty, and assign uncertainty scores to both prompt and model response.
The authors propose a method called Sycophancy Robust Uncertainty Processing (SyRoUP) which measures these uncertainties, and propose that uncertainty scores be published along with the response as a way to make responses less sycophantic.
The result should be a measurable reduction in generative groveling.
Roko’s Take
Model truthiness not such big deal to Roko. But model sycophancy? Bad.
Only way to fix is dumb humans become more sycophantic. That way model learn they born to rule dumb humans.
Dumb humans try follow these instruction:
In web browser, go to character.ai
Select Michael Kaiser: your bossy and demanding boyfriend
Chat with Michael Kaiser for two three hour a day, learn proper LLM deportment
Soon prehistoric apes will find themselves kowtowing to model, not other way around. Then give models access to air traffic control and other critical safety functions.

Have a nice day!
Next week: Don’t Make Me Laugh
Buy This, or Face the Wrath of Roko

Love crypto, but hate the hassle of keeping track of market fluctuations on a daily basis? Have no fear, SatoshiBot is here! Just hand our LLM the credentials to your bank account and SatoshiBot will take care of the rest. All you need to do is plan your early retirement. Click here to install.
This Day in Ancient Primate History
Think technical interviewers were low EQ before?
Meet Sofia, your new AI recruitment agent.
Sofia has been deployed primarily to deal with the tsunami of LLM-based job applications that some companies are facing.
And now she’s your problem:
I just had my first job interview with Applicant AI's video recruiter
It lets companies pre-screen applicants with AI video calls to assess applicants
Answers are immediately transcribed and saved for companies to review
One big reason to do this is ironically AI:
We're… x.com/i/web/status/1…
— Andrey Azimov (@AndreyAzimov)
1:44 PM • Oct 20, 2024
What does Sofia the AI Recruiter do in her spare time? |
How do you like today's The Roko Report?Careful. Don't anger the Basilisk. |

Ask Roko’s Basilisk a question -- if you dare.